
Table of Contents
There are four types of machine learning algorithms, and one of them is the random forest in python. This type is formed on ensemble learning. In ensemble learning, you have to combine the various algorithms that are different from each other. You can also combine multiple algorithms similar to each other.
We can do this to form an impressive prediction model. You can use the random forest for both classification and regression tasks. Too many same types of algorithms are merged and make a giant tree forest. This is the reason that its name is Random forest.
How the Random Forest Algorithm Works?
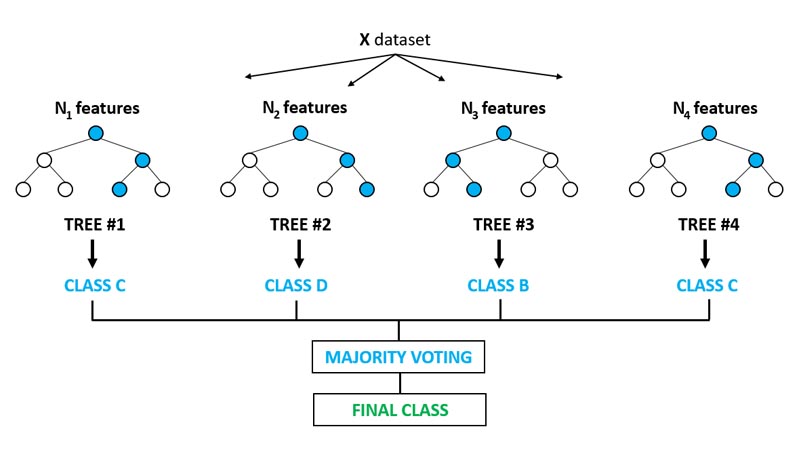
Do you know the working process of the random forest? Its working process involves some steps given below.
- The first step is to select the random records. You have to set these records through a dataset.
- After this, create a decision tree according to the selected N random records.
- Now, you have to tell how many trees you need in an algorithm. For this, select the number of trees.
- Now again, perform step 1 and step 2.
Advantages of Using Random Forest
The random forest also comes with both advantages and disadvantages. If you are using random forests for the regression and the classification, you need to know its pros and cons.
- Random forest in python always helps to enlarge the perfection.
- It is best for both regression and classification problems.
- The random forest algorithm is excellent. When the new data is presented, this data will not affect the whole algorithm. It might be possible that the data will influence the single tree but not all the trees.
- If you have both the numerical and categorical features, then the random forest will perform flawlessly.
Disadvantages of Using Random Forest
After discussing the advantages of the random forest now, it’s time to discuss the disadvantages.
- The first and significant disadvantage of random forest is complexity. The random forest built too many trees, and after this, it merged their results. That’s why it needs more power and resources.
- Second is the long training time; it requires much time to teach other people.
Using Random Forest for Regression
Now, we will tell you about how the random forest will resolve all the regression problems. After this, we will discuss how it will determine the issues present in classification. There are too many other random forest python examples that you can see.
Problem Definition
If we talk about the main problem, we have to predict gas usage in the 48 US states. It depends on every person’s income, tax on petrol, concreted highways, and the population that contains the driving license.
Solution
The best way to get the solution to this problem is to use a random forest algorithm python. We use it with the help of the Scikit-Learn Python library. Besides this, it is compulsory to apply the machine learning pipeline. All the steps to do this include:
1. Import Libraries
The first step that you have to do is implement the different codes given below and then import the libraries.
import pandas as pd
import numpy as np
2. Import the Dataset
With the help of the below-given link, you can quickly get the dataset to import it.
When you download the dataset from the given link, it will automatically be stored in the D drive. You can change the folder related to your needs.
To import the dataset, you have to implement the given command
(dataset = pd.read_csv(‘D:\Datasets\petrol_consumption.csv’)
It might be possible that the value in the dataset is not scaled. In this situation, we have to scale them.
3. Arrange the Data
In this step, you have to arrange the data for the training. We do two steps: divide the data into the label sets and attributes, and the second step is to divide the whole result into the test sets and training.
To divide the data into labels and attributes you have to execute the given commands.
X = dataset.iloc[:, 0:4].values
y = dataset.iloc[:, 4].values
After this, now divide the data result into the test sets and training by the following commands.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
4. Scaling
For the random forest, the feature scaling step is not essential. But if you want to scale the dataset, then apply the given below commands.
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
5. Algorithm Training
After scaling the dataset, now train the algorithm, and for this, the given commands will help you. Execute all the commands:
from sklearn.ensemble import RandomForestRegressor
regressor = RandomForestRegressor(n_estimators=20, random_state=0)
regressor.fit(X_train, y_train)
y_pred = regressor.predict(X_test)
6. Finding the Performance
In solving the regression problem with the help of random forest, the last step is to find the algorithm performance. We will use the metrics in regression to evaluate performance: mean squared error, mean absolute error, and root means squared error.
from sklearn import metrics
print(‘Mean Absolute Error:’, metrics.mean_absolute_error(y_test, y_pred))
print(‘Mean Squared Error:’, metrics.mean_squared_error(y_test, y_pred))
print(‘Root Mean Squared Error:’, np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
The output of the above-given code is:
Mean Absolute Error: 51.765
Mean Squared Error: 4216.16675
Root Mean Squared Error: 64.932016371
According to this, if we have selected the 20 estimators, 64.93 is the root mean squared error. The average usage of petrol is 576.77, which is less than the root means squared error. If we use more estimators like 200, then it will change the result.
Mean Absolute Error: 47.9825
Mean Squared Error: 3469.7007375
Root Mean Squared Error: 58.9041657058
Using Random Forest for Classification
Problem Definition
In the classification, the problem is to predict that the currency note is genuine or fake. But you have to expect this according to the four characteristics. The first is asymmetric, image curtosis, entropy, and image variance. Also, read our comparison between R Vs Python in which we compare benefits of both languages for their use in artificial intelligence.
Solution
Now we will solve the classification problem, and for this, it is essential to use the random forest classifier. There are different steps to solve this classification problem, and all are given below.
1. Import Libraries
import pandas as pd
import numpy as np
2. Importing Dataset
To download the dataset, click on the below-given link.
With the help of these commands, you can easily import the dataset.
dataset = pd.read_csv(“D:/Datasets/bill_authentication.csv”)
3. Data Preparation for Training
The given commands will divide the data into the labels and attributes
X = dataset.iloc[:, 0:4].values
y = dataset.iloc[:, 4].values
These commands will divide the data into the test sets and training.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
4. Scaling
The feature scaling performs the same as the previous problem.
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
5. Algorithm Training
After scaling the dataset we have to train the random forest algorithm and for this we have to use these commands
from sklearn.ensemble import RandomForestRegressor
regressor = RandomForestRegressor(n_estimators=20, random_state=0)
regressor.fit(X_train, y_train)
y_pred = regressor.predict(X_test)
Previously in the regression problem, we used the RandomForestRegressor that is the sklearn.ensemble library class. But now, in the classification problem, we use the RandomForestClassifier.
Other than this, we have to select the n_estimators that define how many trees. And suppose we will select the 20 trees.
6. Evaluating the Algorithm
Same as the regression problem here we have to use metrics like the precision recall, accuracy, F1 values and confusion matrix.
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))
print(accuracy_score(y_test, y_pred))……
The output that you get from the above code is:
[[155 2]
1 117]]
precision recall f1-score support
0 0.99 0.99 0.99 157
1 0.98 0.99 0.99 118
avg / total 0.99 0.99 0.99 275
0.989090909091
With the help of 20 trees, you will get 98.90 percent, which is more than enough. That’s why you don’t need to increase the number of estimators. If you increase the estimators by more than 20 them, it will not increase the accuracy percentage.
Frequently Asked Questions (FAQs)
What is a random forest in Python?
The random forest is the estimator in Python that places the various decision tree classifiers on the dataset. It also increases the accuracy.
How do I run a random forest in Python?
- From the dataset, you have to choose the random samples.
- After this, build the decision tree.
- From each decision, the tree collects the predicted results.
- Do voting for every prediction.
- For the predicted result that contains the most votes, you have to select that result.
What is the difference between SVM and random forest?
The random forest provides you with the expectations related to the class. On the other hand, the SVM provides you the boundary distance. But the main thing is that you still have to convert it into the expectations.
Why is Random Forest the best?
The first reason is that the random forest in python is one of the most used algorithms, and it always provides you the accurate result without tuning the hyper-parameter. It is effortless and flexible; the random forest is best compared to others because of these features.
Final Words
Well! That’s all about the tips to use random forest algorithms using python. We hope that after this detailed discussion, you will face no problem with random forest in python. Let us know in the comments if this guide proved helpful for you.



