Table of Contents
In the vast ocean of data that surrounds us, innovative data science projects stand as lighthouses, guiding us to new shores of understanding and decision-making. These projects, leveraging the latest in machine learning and big data technologies, transform the complex and often chaotic world of big data into clear, actionable insights. This article delves into the transformative power of data science, exploring how cutting-edge projects are reshaping industries, enhancing business strategies, and empowering aspiring data scientists to build impactful careers.
Key Takeaways
- Advanced analytics projects, particularly those utilizing Apache Spark, are revolutionizing the speed and scalability of insights derived from big data.
- Effective data cleaning and preparation are crucial for the success of data science projects, with a direct impact on the robustness and accuracy of predictive models.
- Choosing the right dataset and understanding the data science project lifecycle are essential steps toward generating innovative insights and achieving project success.
- The strategic integration of data science into business operations can significantly optimize performance and drive informed decision-making.
- Hands-on experience with real-world data science projects is invaluable for career advancement and mastering the skills required to become a proficient data scientist.
Harnessing the Power of Machine Learning and Big Data

Exploring Apache Spark’s Role in Advanced Analytics
Apache Spark has emerged as a cornerstone in the realm of big data analytics, offering a robust platform for handling large-scale data processing. Its in-memory processing capabilities enhance performance significantly, making it an ideal choice for complex analytical tasks. Spark’s fault tolerance and comprehensive analytics engine support a wide range of applications, from batch processing to real-time analytics.
The core components of Spark, including Spark SQL, Spark Streaming, MLlib, and GraphX, each play a critical role in the ecosystem. These components are designed to work in harmony, providing a seamless experience for data scientists and engineers:
- Spark SQL for structured data processing
- Spark Streaming for real-time data ingestion
- MLlib for machine learning
- GraphX for graph processing
Spark’s versatility extends to its integration with various data sources and storage systems, making it a versatile tool in the big data space.
As the demand for advanced analytics grows, Spark’s role in enabling organizations to derive insights from big data becomes ever more crucial. Projects leveraging Spark are diverse, ranging from link prediction and cloud hosting to data analysis and speech analysis, demonstrating its broad applicability.
Case Studies: Real-World Applications of Machine Learning
The realm of machine learning is replete with examples where data science has been a game-changer across various industries. Machine learning case studies often reveal the transformative power of this technology in solving complex problems and generating actionable insights.
For instance, consider the application of machine learning in predicting loan defaults. By leveraging Explainable AI models, financial institutions can better assess risk and make informed lending decisions. Similarly, in the telecom sector, multi-level classification models are employed to predict customer churn, enabling companies to retain valuable clients.
- Loan Default Prediction using Explainable AI
- Lead Scoring Model in Python
- Churn Prediction in Telecom
These projects not only showcase the practicality of machine learning but also serve as a testament to its potential in driving innovation. As we delve into these case studies, we uncover the intricate dance between data, algorithms, and domain expertise that leads to successful outcomes.
Overcoming Challenges in Big Data Processing
Leveraging Apache Spark for machine learning projects offers immense potential to extract meaningful insights from big data. However, developers often encounter specific challenges that can impede the efficiency and effectiveness of their machine learning endeavors. Understanding these challenges — and knowing how to navigate them — is crucial for harnessing Spark’s full potential.
While deploying Spark for machine learning projects comes with its set of challenges, strategic solutions can significantly mitigate their impact. Effective management of resource allocation, ensuring data quality, and tuning machine learning models for optimal performance are key to unlocking Spark’s transformative potential in big data analytics.
Challenges in big data processing with Spark can be addressed through a variety of strategies:
- Data Partitioning & Caching: Utilize Spark’s capabilities to enhance processing speed by ensuring data is evenly distributed and frequently accessed data is stored in memory.
- Integration with Big Data Tools: Enhance data ingestion and analysis by integrating Spark with complementary big data tools.
- Resource Management: Allocate computational resources strategically to handle intricate machine learning algorithms efficiently.
Embracing these best practices not only helps in overcoming the hurdles but also paves the way for advanced analytics that can transform industries.
Data Cleaning and Preparation: The Unsung Heroes of Data Science

Essential Data Cleaning Techniques for Robust Models
In the realm of data science, data cleaning is a pivotal step that ensures the reliability and accuracy of machine learning models. It involves a series of processes aimed at correcting or removing incorrect, corrupted, or irrelevant parts of the data.
- Cleaning: It is crucial to remove errors and inconsistencies to maintain data quality. This step often includes normalizing text data and handling missing values.
- Integrating: Data from various sources must be harmonized through techniques such as joining and appending, which helps in creating a comprehensive dataset.
- Transforming: Before data can be effectively used for modeling, it often requires transformation. This may involve reducing the number of variables or encoding categorical data using dummy variables.
By diligently applying these techniques, data scientists can significantly enhance the robustness of their predictive models. Moreover, these practices are not just theoretical; they are essential skills for those looking to thrive in data science careers, especially as AI and big data are transforming industries.
While the process can be complex, the use of data validation frameworks and comprehensive data cleaning pipelines can automate and streamline these tasks, leading to more accurate and reliable machine learning models.
Projects to Master Data Preprocessing
Mastering data preprocessing is a critical step in the journey of a data scientist. It involves transforming raw data into a format that is suitable for analysis. Projects that focus on data preprocessing skills are essential for anyone looking to excel in data science. These projects often include tasks such as normalizing text data, handling missing data, and identifying outliers.
Data preprocessing is not just about cleaning data; it’s about setting the stage for insightful analytics.
Here are some projects to consider adding to your data science portfolio:
- Predictive Analytics Project for Working Capital Optimization
- MLOps Project to Build Search Relevancy Algorithm with SBERT
- Build an AI Chatbot from Scratch using the Keras Sequential Model
Each project offers a unique challenge in data cleaning and preparation, from exploratory data analysis to advanced techniques like feature engineering. By working on these projects, you can demonstrate your ability to turn messy, real-world data into actionable insights.
The Impact of Data Quality on Predictive Analytics
The foundation of predictive analytics lies in the quality of the data fed into the models. High-quality data is paramount for the accuracy and reliability of predictions. Inaccuracies, inconsistencies, or incomplete data can lead to flawed insights and poor decision-making.
The integrity of data shapes the effectiveness of predictive models, making data cleaning and preparation critical steps in the data science process.
Here are some common data quality issues that can impact predictive analytics:
- Inaccurate data due to human error or measurement inaccuracies
- Incomplete datasets that lack critical information
- Inconsistent data arising from different sources or formats
- Biased data that can lead to skewed predictions
Addressing these issues is essential for organizations to leverage predictive analytics effectively. It requires a systematic approach to data management and a keen understanding of the data’s origin and context.
Navigating the Data Science Project Landscape

Selecting the Right Dataset for Your Analysis
The foundation of any data science project lies in the dataset chosen for analysis. Selecting the right dataset is crucial as it directly impacts the insights you can derive and the overall success of the project. Here are some key considerations:
- Relevance: Ensure the dataset aligns with your project goals.
- Quality: Look for datasets with high accuracy and completeness.
- Size: The dataset should be sufficiently large for robust analysis.
- Accessibility: It should be readily available for use.
When embarking on your data science venture, consider the 2024 Ultimate Guide: 90+ Free Datasets for Data Science, which offers a plethora of resources for machine learning, visualization, NLP, and more. This guide can be a starting point to elevate your project with the right data.
The choice of dataset not only influences the potential outcomes but also dictates the tools and techniques required for analysis. It’s a decision that sets the stage for the entire analytical process.
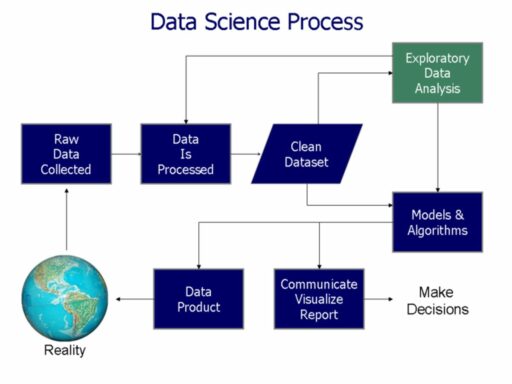
From Concept to Deployment: A Project Lifecycle Overview
The journey from an initial concept to a fully deployed data science project is intricate and multifaceted. The life cycle of a data science project typically encompasses several stages, each critical to the project’s success. Here is a brief overview of these stages:
- Data Acquisition: Gathering the necessary data from various sources.
- Data Preparation: Cleaning and organizing data for analysis.
- Hypothesis and Modeling: Developing models to test theories and predictions.
- Evaluation and Interpretation: Assessing the model’s performance and drawing conclusions.
- Deployment: Implementing the model into a production environment.
- Operations/Maintenance: Ensuring the model remains accurate and efficient over time.
An integrated approach to project management, where insights and decisions are shared collectively, not only harnesses the diverse expertise within the team but also promotes a sense of ownership and accountability toward the project’s outcomes.
This structured approach to project management, underpinned by sophisticated data analysis, fosters a culture of transparency, agility, and continuous improvement. The result is a more cohesive, informed, and effective project team capable of navigating complexities and successfully completing projects.
Leveraging Public Data Sources for Innovative Insights
The wealth of public data sources available today offers unprecedented opportunities for data scientists to explore and innovate. Platforms like Kaggle and the UCI Machine Learning Repository have become go-to resources for those seeking diverse datasets for analysis. These repositories provide a wide range of data, from social media feeds to financial market information, enabling the creation of insightful analytics projects.
The key to harnessing these resources lies in understanding how to effectively navigate and utilize them for maximum impact.
Real-time data sources, such as the Twitter API or Pew Research Center’s datasets, are particularly valuable for capturing the pulse of current events and societal trends. By tapping into these streams, data scientists can conduct sentiment analysis, track public opinion shifts, and even predict cultural movements.
Here’s a quick guide to some of the most useful public data sources:
- Kaggle: A platform for data science competitions and datasets
- UCI Machine Learning Repository: A collection of databases for empirical analysis
- GitHub: A hub for collaborative projects, including data-rich repositories
- Twitter API: Provides access to real-time social media data
- Pew Research Center: Offers datasets for exploring societal trends
Data science expertise is in high demand, offering measurable market results. Steps to become a data scientist include degrees in IT, data science, and sector experience. Related posts cover BI, ML, and SEO strategies.
The Intersection of Data Science and Business Strategy

Optimizing Operations with Predictive Analytics
Predictive analytics is revolutionizing the way businesses optimize their operations. By harnessing the power of machine learning algorithms, companies can now anticipate future challenges and streamline their processes for maximum efficiency. Financial forecasting in the financial sector is a prime example, where real-time analysis of market data and social media sentiments leads to accurate market trend predictions and fraud detection.
In the realm of supply chain management, predictive analytics is a game-changer. Clustering algorithms and regression models are employed to forecast demand and inventory levels, significantly reducing operational costs. For instance:
- Forecasting demand to maintain optimal inventory levels
- Predicting potential supply chain disruptions
- Optimizing routes and logistics for efficiency
Predictive analytics not only provides a competitive edge but also enhances the ability to respond to market dynamics proactively. It’s a strategic tool that transforms vast amounts of data into actionable insights, ultimately driving better business decisions.
The application of predictive analytics extends beyond these examples. In healthcare, it aids in early intervention strategies and in project management, it serves as an advanced warning system for potential risks. The key to success lies in the effective use of AI algorithms to leverage data, offering foresight that enables proactive strategies and a nuanced approach to risk management.
Driving Business Decisions Through Data-Driven Insights
In the realm of business strategy, data-driven insights serve as a compass guiding companies through the complex landscape of decision-making. Business intelligence software plays a pivotal role in this journey, enabling organizations to extract valuable insights from big data. This process encompasses data collection, analysis, situational awareness, decision support, and risk management, ultimately enhancing decision-making, competitiveness, and customer satisfaction.
The Data Science Process offers a structured approach to harnessing the power of data, enabling organizations to derive actionable insights and drive strategic decision-making.
By leveraging advanced analytics, businesses can not only respond to current market conditions but also anticipate future trends and customer needs. This proactive stance is crucial for maintaining a competitive edge in today’s fast-paced business environment. The following table illustrates the impact of data-driven insights on various business aspects:
| Aspect | Impact of Data-Driven Insights |
|---|---|
| Decision-Making | Improved accuracy and confidence |
| Competitiveness | Enhanced market positioning |
| Customer Satisfaction | Increased through personalized experiences |
| Operational Efficiency | Streamlined processes and cost savings |
| Product Development | Innovative and customer-centric solutions |
In conclusion, the integration of data analytics and deep practitioner knowledge into business strategy is not just beneficial but indispensable for achieving project success and driving informed decisions that propel an organization forward.
Case Study: Transforming Industries with Data Science
The integration of data science into industry practices has revolutionized the way businesses operate. Data-driven companies are now leveraging insights from big data to innovate and gain a competitive edge. For instance, CodeStringers have harnessed the power of data across various decision-making processes, including new product creation, supply chain management, and marketing analytics.
| Industry | Application | Outcome |
|---|---|---|
| Retail | Supply Chain Optimization | Increased Efficiency |
| Finance | Risk Assessment | Reduced Risk |
| Healthcare | Patient Data Analysis | Improved Care |
| Marketing | Consumer Behavior Insights | Enhanced Targeting |
The essence of data science is undergoing a profound transformation, shifting from manual tasks to more complex analyses and strategic planning.
By industrializing the analysis process and integrating it with other tools, businesses ensure a systematic approach that leads to actionable outcomes. The benefits of such a transformation are manifold, from improved decision-making and operational efficiency to innovative product development and increased competitiveness.
Building a Career in Data Science

Essential Skills for Aspiring Data Scientists
As the field of data science continues to evolve, certain core competencies remain critical for those looking to enter the profession. Proficiency in programming languages like Python or R is indispensable, as these tools form the backbone of data manipulation and analysis. Familiarity with libraries such as Pandas, Matplotlib, and Seaborn is equally important for effective data handling and visualization.
- Data Analysis: Identifying trends and patterns in large datasets.
- Data Visualization: Creating clear, insightful visual representations.
- Predictive Modeling: Building models to forecast future trends.
- Statistical Analysis: Applying statistical methods to interpret data accurately.
- Data Cleaning: Preparing large datasets for analysis through thorough cleaning and preprocessing.
Mastery of these skills enables aspiring data scientists to transform raw data into actionable insights, paving the way for innovative solutions across various industries. Continuous learning and staying abreast of the latest advancements are also essential, as the landscape of data science is perpetually shifting. Embracing these challenges and opportunities is key to a successful career in this dynamic field.
Navigating the Job Market: Tips and Strategies
Entering the data science job market can be as challenging as it is exciting. Networking is key; building professional relationships can lead to opportunities that are not advertised publicly. Attend industry conferences, participate in online forums, and join data science groups to expand your network.
- Update Your Resume: Tailor it to highlight relevant projects and skills.
- Practice for Interviews: Focus on technical and behavioral questions.
- Stay Informed: Keep up with industry trends and emerging technologies.
- Be Open to Learning: Show willingness to learn and adapt to new tools and methodologies.
In the rapidly evolving field of data science, continuous learning and adaptability are not just beneficial, they are essential for long-term career success.
When considering job offers, evaluate not just the salary but also the professional growth opportunities, company culture, and the potential for work-life balance. Remember, the right fit is crucial for both personal satisfaction and career development.
Realizing the Value of Hands-on Project Experience
The culmination of a data scientist’s education is not found in textbooks, but in the trenches of real-world problem-solving. Hands-on project experience stands as the cornerstone of a successful data science career, bridging the gap between theoretical knowledge and practical expertise.
By engaging in hands-on projects, individuals not only sharpen their technical skills but also cultivate the soft skills necessary to convey complex findings effectively.
Here are some key benefits of hands-on project experience:
- Application of theoretical concepts to solve practical problems
- Development of a portfolio showcasing a range of skills and accomplishments
- Exposure to the end-to-end lifecycle of data science projects
- Opportunity to work with real datasets, simulating industry challenges
Aspiring data scientists should consider the following steps to maximize the learning from their projects:
- Start with projects aligned with your current skill level and gradually progress to more complex challenges.
- Focus on projects that offer the chance to work with diverse datasets and scenarios.
- Regularly reflect on the outcomes and lessons learned from each project to continuously improve.
Embracing hands-on projects is not just about technical growth; it’s about gaining the confidence to make data-driven decisions and becoming a lifelong learner in the ever-evolving field of data science.
Conclusion
The journey through innovative data science projects has been a testament to the transformative power of big data and the insights it can yield. From beginners to advanced practitioners, the projects discussed offer a rich tapestry of opportunities to harness datasets for real-world problem solving. Whether through the speed and scalability of Apache Spark, the meticulous process of data cleaning, or the predictive prowess of machine learning, these projects underscore the critical role of data science in today’s analytics-driven landscape. As we continue to push the boundaries of what’s possible with data, the projects featured in this article serve as both a foundation and inspiration for aspiring data scientists to build upon. The future of analytics is bright, and it is the innovative application of data science that will illuminate the path forward.
Frequently Asked Questions
What is the role of Apache Spark in advanced analytics?
Apache Spark plays a crucial role in advanced analytics by providing a powerful platform for big data processing and machine learning tasks. It enables high-speed analytics and data processing, allowing for the extraction of insights with unprecedented speed and scalability.
How can I find interesting datasets for my data science projects?
You can find interesting datasets for data science projects on platforms like Kaggle, the UCI Machine Learning Repository, or by utilizing APIs for real-time data. Web scraping tools can also be used to collect data from websites, and you can consider using personal or work-related data while adhering to privacy and ethical guidelines.
Why is data cleaning important in data science?
Data cleaning is critical in data science because it ensures the quality and accuracy of the data used for analysis. Clean data leads to more robust models, better insights, and more reliable predictive analytics, ultimately affecting the success of data-driven decisions.
What are some data analytics projects for beginners?
Beginners can start with projects like analyzing customer behavior, predicting market trends, or working on data-cleaning projects that involve exploratory data analysis. These projects help in understanding the basics of data science and building foundational skills.
How does data science transform business strategy?
Data science transforms business strategy by providing data-driven insights that can optimize operations, forecast trends, and inform strategic decisions. It allows businesses to leverage predictive analytics to stay competitive and to innovate within their industries.
What skills are essential for aspiring data scientists?
Aspiring data scientists should focus on developing skills in programming (e.g., Python, R), machine learning, statistics, data visualization, and data manipulation. Additionally, they should have a strong understanding of the domain they wish to work in and the ability to communicate insights effectively.